线段树是一种非常美的数据结构,她不仅可以拿来维护数组里的信息并支持快速查询以及修改,还能广泛的应用在其他算法的优化中。这篇文章记录着我对线段树的全部理解。
2.6 文章创建,写了最最基础的线段树。
3.3 增加了懒标记这个东西 但只是举了区间加这个例子。
8.6 阅读了这篇博客 ,重写了整篇文章并发布在了洛谷专栏
线段树是我们经常会使用的一种可以在O(log n) \text{O(log n)} O(log n)
线段树的基本结构就是把整个数组划分成许多区间,并用树的结构递归求解的数据结构。
这样直接描述感觉还是让人听不懂,一个长度为8的线段树就可以被建立为下面这样的线段树:
不难发现,根节点就直接维护了整个数组,接下去之后的每个非叶子节点都被等分为了两端儿子,来维护当前节点维护的信息。
我们拿维护数组区间和的线段树举例子 。
对于每个节点,我们需要维护这个节点对应原本数组的左端点l \text{l} l r \text{r} r
建树代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 struct node { int l, r, val; }bit[111111 << 2 ]; void pushup (int x) bit[x].val = bit[x << 1 ].val + bit[x << 1 | 1 ].val; } void build (int x, int l, int r) bit[x].l = l; bit[x].r = r; if (l == r) { bit[x].val = init[l]; return ; } int mid = (l + r) / 2 ; if (l <= mid) { build (x << 1 , l, mid); } if (mid < r) { build (x << 1 | 1 , mid + 1 , r); } pushup (x); }
这里我们代码里维护了一个node \text{node} node
build \text{build} build
如果当前节点需要维护的左端点等于右端点的时候,就代表了这个节点要维护的只有一个元素,所以这里不再递归下去,直接把节点的val \text{val} val
对于一个节点我们要怎么知道这一段的区间和呢?pushup \text{pushup} pushup
那这么建树有什么好处呢?继续往下看。
还是刚才那个数组,我们要修改一个点:
可以发现,每次修改一个点,只会对它和它的父亲节点 产生影响。那我们如何在O(log n) \text{O(log n)} O(log n)
不难想到可以直接递归到要修改的那个点的位置,然后直接更改对应节点的val \text{val} val pushdown \text{pushdown} pushdown
这样就解决了单点修改的问题,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void update (int x, int pos, int k) if (bit[x].l == pos && bit[x].r == pos) { bit[x].val += k; return ; } int mid = (bit[x].l + bit[x].r) / 2 ; if (pos <= mid) { update (x << 1 , pos, k); } if (mid < pos) { update (x << 1 | 1 , pos, k); } pushup (x); }
这里有的人可能不会理解pushup \text{pushup} pushup if \text{if} if
首先我们保证了要修改的位置pos \text{pos} pos
左儿子,区间[ l , m i d ] [l, mid] [ l , m i d ]
右儿子,区间[ m i d + 1 , r ] [mid + 1, r] [ m i d + 1 , r ]
这里我们保证了p o s ∈ [ l , r ] pos \in [l,r] p o s ∈ [ l , r ] p o s ≤ m i d pos \leq mid p o s ≤ m i d m i d + 1 ≤ p o s mid + 1 \leq pos m i d + 1 ≤ p o s 1 1 1 m i d < p o s mid < pos m i d < p o s
我们在之前的代码里就已经保证了每一次操作过后,每一个节点所维护的值都是最新的状态,那么区间查询的思路其实就十分简单了。
我们直接往下递归,要是当前的节点的左端点和右端点在区间外,就直接返回0;要是当前的节点在区间内就直接返回当前节点的值;要是都不满足,就直接往左儿子和右儿子递归即可。
1 2 3 4 5 6 7 8 9 10 int query (int x, int l, int r) if (bit[x].l >= l && bit[x].r <= r) { return bit[x].val; } if (bit[x].r < l || r < bit[x].l) { return 0 ; } return query (x << 1 , l, r) + query (x << 1 | 1 , l, r); }
本题无题面。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 #include <bits/stdc++.h> using namespace std;#define int long long struct node { int l, r, val; }bit[111111 << 2 ]; void pushup (int x) bit[x].val = bit[x << 1 ].val + bit[x << 1 | 1 ].val; } vector<int > init; void build (int x, int l, int r) bit[x].l = l; bit[x].r = r; if (l == r) { bit[x].val = init[l]; return ; } int mid = (l + r) / 2 ; if (l <= mid) { build (x << 1 , l, mid); } if (mid < r) { build (x << 1 | 1 , mid + 1 , r); } pushup (x); } void update (int x, int pos, int k) if (bit[x].l == pos && bit[x].r == pos) { bit[x].val += k; return ; } int mid = (bit[x].l + bit[x].r) / 2 ; if (pos <= mid) { update (x << 1 , pos, k); } if (mid < pos) { update (x << 1 | 1 , pos, k); } pushup (x); } int query (int x, int l, int r) if (bit[x].l >= l && bit[x].r <= r) { return bit[x].val; } if (bit[x].r < l || r < bit[x].l) { return 0 ; } return query (x << 1 , l, r) + query (x << 1 | 1 , l, r); } signed main () int n, m; cin >> n >> m; init.resize (n + 1 ); for (int i = 1 ; i <= n; i++) { cin >> init[i]; } build (1 , 1 , n); while (m--) { int ch; cin >> ch; if (ch == 1 ) { int p, k; cin >> p >> k; update (1 , p, k); } else { int l, r; cin >> l >> r; cout << query (1 , l, r) << '\n' ; } } }
在这个版本里其实与上面单点修改的代码有异曲同工之妙,稍微改一改就能改出这个的代码。
我们还是直接往下递归,但是要像区间查询那样判断当前节点与要修改区间的情况来选择哪些儿子要继续递归下去,判断方式基本一样。
因为为了让所有节点都保持最新状态,你需要一直递归到叶子节点,这样往上更新才能满足我们的条件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void update (int x, int l, int r, int k) if (bit[x].l == bit[x].r) { bit[x].val += k; return ; } int mid = (bit[x].l + bit[x].r) / 2 ; if (l <= mid) { update (x << 1 , l, r, k); } if (mid < r) { update (x << 1 | 1 , l, r, k); } pushup (x); }
这里区间查询的思路和代码与前面完全一样,不再赘述。没有理解的可以去看一看前面单点修改部分的查询思路。
题目链接
如题,已知一个数列 { a i } \{a_i\} { a i }
将某区间每一个数加上 k k k
求出某区间每一个数的和。
第一行包含两个整数 n , m n, m n , m
第二行包含 n n n a i a_i a i i i i i i i
接下来 m m m 3 3 3 4 4 4
1 x y k:将区间 [ x , y ] [x, y] [ x , y ] k k k 2 x y:输出区间 [ x , y ] [x, y] [ x , y ]
输出包含若干行整数,即为所有操作 2 的结果。
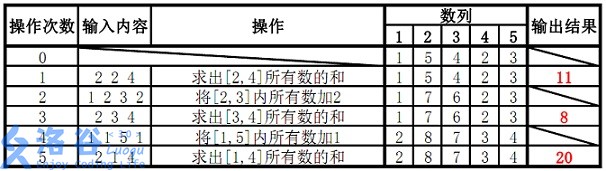
1 2 3 4 5 6 7 5 5 1 5 4 2 3 2 2 4 1 2 3 2 2 3 4 1 1 5 1 2 1 4
对于 15 % 15\% 1 5 % n ≤ 8 n \le 8 n ≤ 8 m ≤ 10 m \le 10 m ≤ 1 0 35 % 35\% 3 5 % n ≤ 10 3 n \le {10}^3 n ≤ 1 0 3 m ≤ 10 4 m \le {10}^4 m ≤ 1 0 4 100 % 100\% 1 0 0 % 1 ≤ n , m ≤ 10 5 1 \le n, m \le {10}^5 1 ≤ n , m ≤ 1 0 5 a i , k a_i,k a i , k 2 × 1 0 18 2\times 10^{18} 2 × 1 0 1 8
【样例解释】
提交记录 ,这里只拿到了45 45 4 5
原因当然是时间复杂度不对,通过这道题需要用到后面线段树进阶中的一个技巧——懒标记 ,请理解这里的内容后再去学习懒标记。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 #include <bits/stdc++.h> using namespace std;#define int long long struct node { int l, r, val; }bit[111111 << 2 ]; void pushup (int x) bit[x].val = bit[x << 1 ].val + bit[x << 1 | 1 ].val; } vector<int > init; void build (int x, int l, int r) bit[x].l = l; bit[x].r = r; if (l == r) { bit[x].val = init[l]; return ; } int mid = (l + r) / 2 ; if (l <= mid) { build (x << 1 , l, mid); } if (mid < r) { build (x << 1 | 1 , mid + 1 , r); } pushup (x); } void update (int x, int l, int r, int k) if (bit[x].l == bit[x].r) { bit[x].val += k; return ; } int mid = (bit[x].l + bit[x].r) / 2 ; if (l <= mid) { update (x << 1 , l, r, k); } if (mid < r) { update (x << 1 | 1 , l, r, k); } pushup (x); } int query (int x, int l, int r) if (bit[x].l >= l && bit[x].r <= r) { return bit[x].val; } if (bit[x].r < l || r < bit[x].l) { return 0 ; } return query (x << 1 , l, r) + query (x << 1 | 1 , l, r); } signed main () int n, m; cin >> n >> m; init.resize (n + 1 ); for (int i = 1 ; i <= n; i++) { cin >> init[i]; } build (1 , 1 , n); while (m--) { int ch; cin >> ch; if (ch == 1 ) { int l, r, k; cin >> l >> r >> k; update (1 , l, r, k); } else { int l, r; cin >> l >> r; cout << query (1 , l, r) << '\n' ; } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 struct segtree { struct node { int l, r, val; }; int n, lp, rp; vector<node> bit; vector<int > init; explicit segtree (int _n) : n(_n), lp(1 ), rp(n) // 初始化,维护1 ~n,初始为0 { bit.resize (n << 1 + 1 , {0 , 0 , 0 }), build (1 , 1 , n), init.resize (n + 1 , 0 ); } explicit segtree (int _n, int _l, int _r) : n(_n), lp(_l), rp(_r) // 初始化,维护l~r,初始为0 { bit.resize (n << 1 + 1 , {0 , 0 , 0 }), build (1 , _l, _r); init.resize (_r + 1 , 0 ); } explicit segtree (int _n, int _l, int _r, vector<int > _init) : n(_n), lp(_l), rp(_r) // 初始化,维护l~r,初始为_init数组 { bit.resize (n << 1 + 1 , {0 , 0 , 0 }), build (1 , _l, _r), init.resize (n + 1 , 0 ); } void pushup (int x) { bit[x].val = bit[x << 1 ].val + bit[x << 1 | 1 ].val; } void build (int x, int l, int r) { bit[x].l = l; bit[x].r = r; if (l == r) { bit[x].val = init[l]; return ; } int mid = (l + r) / 2 ; if (l <= mid) { build (x << 1 , l, mid); } if (mid < r) { build (x << 1 | 1 , mid + 1 , r); } pushup (x); } int query (int x, int l, int r) { if (l <= bit[x].l && bit[x].r <= r) { return bit[x].val; } if (l > bit[x].r || bit[x].l > r) { return 0 ; } return query (x << 1 , l, r) + query (x << 1 | 1 , l, r); } int query (int l, int r) { assert (lp <= l && l <= r && r <= rp); return query (1 , l, r); } void update (int x, int l, int r, int k) { if (bit[x].l == bit[x].r) { bit[x].val += k; return ; } if (bit[x].l > r || l > bit[x].r) { return ; } int mid = (bit[x].l + bit[x].r) / 2 ; if (l <= mid) { update (x << 1 , l, r, k); } if (mid < r) { update (x << 1 | 1 , l, r, k); } pushup (x); } void update (int l, int r, int k) { assert (lp <= l && l <= r && r <= rp); update (1 , l, r, k); } };
请理解了前面的内容后再来阅读这里的内容。
我们在线段树初步里讲区间修改+区间查询的时候给了洛谷P3372 线段树模板题 的45 45 4 5
我们在区间查询的代码时,对于一个完全被覆盖在区间里 的节点,我们也是继续递归下去到叶子节点,这样来保证查询的时候每个节点都是最新状态,这就是超时的瓶颈所在。
那我们应该怎么办呢?
假如当前节点维护的区间是[ l , r ] [l,r] [ l , r ] k k k k ∗ ( r − l + 1 ) k*(r-l+1) k ∗ ( r − l + 1 )
所以如果我们只修改当前节点的区间和,对于它以及它的父亲节点以上的查询其实都是没有什么影响的。
问题就在于要是我们直接这样修改,它的儿子们都还是老版本,这该怎么办呢?可能的思路是在查询到儿子节点的时候把提前我们偷懒 没有修改的这个k k k
要是你看懂了上面的东西,其实你就能理解懒标记在干什么了。
当更改信息的时候,这一整个区间都已经在修改范围内了,你就偷懒只更改了这个区间。
但是一旦询问到了这个节点的儿子节点,你就必须把之前偷懒的东西给下传,这个时候我们对于每个节点node \text{node} node lazy \text{lazy} lazy
这么说你还是可能听不太懂,所以你可以去看看下面的代码。
首先就是我们结构体的定义要改变,要多一个lazy \text{lazy} lazy
1 2 3 4 struct node { int l, r, val, lazy; };
然后就是我们需要写一个pushdown \text{pushdown} pushdown
1 2 3 4 5 6 7 8 9 10 void pushdown (int x) if (bit[x].lazy) { bit[x << 1 ].lazy += bit[x].lazy; bit[x << 1 | 1 ].lazy += bit[x].lazy; bit[x << 1 ].val += bit[x].lazy * (bit[x << 1 ].r - bit[x << 1 ].l + 1 ); bit[x << 1 | 1 ].val += bit[x].lazy * (bit[x << 1 | 1 ].r - bit[x << 1 | 1 ].l + 1 ); bit[x].lazy = 0 ; } }
需要注意的是这里我们下传过后要及时清空这个节点的懒标记。
那对于区间修改,我们根据懒标记的定义就可以写出这样的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void update (int x, int l, int r, int k) if (l <= bit[x].l && bit[x].r <= r) { bit[x].val += k * (bit[x].r - bit[x].l + 1 ); bit[x].lazy += k; return ; } if (bit[x].l > r || l > bit[x].r) { return ; } pushdown (x); update (x << 1 , l, r, k); update (x << 1 | 1 , l, r, k); pushup (x); }
区间查询也同理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int query (int x, int l, int r) if (l <= bit[x].l && bit[x].r <= r) { return bit[x].val; } if (l > bit[x].r || bit[x].l > r) { return 0 ; } pushdown (x); int res = 0 ; if (l <= bit[x << 1 ].r) res += query (x << 1 , l, r); if (r >= bit[x << 1 | 1 ].l) res += query (x << 1 | 1 , l, r); return res; }
题目链接
这里题目描述在这篇文章的前面就有了。
提交记录 这回终于是100分了
这里我封装了一下这个东西:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 #include <bits/stdc++.h> using namespace std;#define int long long struct lazysegtree { struct node { int l, r, val, lazy; }; int n, lp, rp; vector<int > init; vector<node> bit; explicit lazysegtree (int _n) : n(_n), lp(1 ), rp(_n) // 初始化,维护1 ~n,初始为0 { bit.resize ((_n << 2 ) + 1 ); / init.resize (_n + 1 , 0 ); build (1 , 1 , n); } explicit lazysegtree (int _n, int _l, int _r) : n(_n), lp(_l), rp(_r) // 初始化,维护l~r,初始为0 { bit.resize ((_n << 2 ) + 1 ); / init.resize (_r + 1 , 0 ); build (1 , _l, _r); } explicit lazysegtree (vector<int > _init, int _l, int _r) : n(_r - _l + 1 ), lp(_l), rp(_r) // 初始化,维护l~r,初始为_init数组 { bit.resize ((n << 2 ) + 1 ); init = _init; build (1 , _l, _r); } void pushup (int x) { bit[x].val = bit[x << 1 ].val + bit[x << 1 | 1 ].val; } void pushdown (int x) { if (bit[x].lazy) { bit[x << 1 ].lazy += bit[x].lazy; bit[x << 1 | 1 ].lazy += bit[x].lazy; bit[x << 1 ].val += bit[x].lazy * (bit[x << 1 ].r - bit[x << 1 ].l + 1 ); bit[x << 1 | 1 ].val += bit[x].lazy * (bit[x << 1 | 1 ].r - bit[x << 1 | 1 ].l + 1 ); bit[x].lazy = 0 ; } } void build (int x, int l, int r) { bit[x].l = l; bit[x].r = r; bit[x].lazy = 0 ; if (l == r) { bit[x].val = init[l]; return ; } int mid = (l + r) / 2 ; build (x << 1 , l, mid); build (x << 1 | 1 , mid + 1 , r); pushup (x); } int query (int x, int l, int r) { if (l <= bit[x].l && bit[x].r <= r) { return bit[x].val; } if (l > bit[x].r || bit[x].l > r) { return 0 ; } pushdown (x); int res = 0 ; if (l <= bit[x << 1 ].r) res += query (x << 1 , l, r); if (r >= bit[x << 1 | 1 ].l) res += query (x << 1 | 1 , l, r); return res; } int query (int l, int r) { assert (lp <= l && l <= r && r <= rp); return query (1 , l, r); } void update (int x, int l, int r, int k) { if (l <= bit[x].l && bit[x].r <= r) { bit[x].val += k * (bit[x].r - bit[x].l + 1 ); bit[x].lazy += k; return ; } if (bit[x].l > r || l > bit[x].r) { return ; } pushdown (x); update (x << 1 , l, r, k); update (x << 1 | 1 , l, r, k); pushup (x); } void update (int l, int r, int k) { assert (lp <= l && l <= r && r <= rp); update (1 , l, r, k); } }; signed main () int n, m; cin >> n >> m; vector<int > a (n + 1 ) ; for (int i = 1 ; i <= n; i++) { cin >> a[i]; } lazysegtree seg (a, 1 , n) ; while (m--) { int ch; cin >> ch; if (ch == 1 ) { int l, r, k; cin >> l >> r >> k; seg.update (l, r, k); } else { int l, r; cin >> l >> r; cout << seg.query (l, r) << '\n' ; } } return 0 ; }
懒标记还有在维护分治信息有更高阶的应用,这里在后面会提到。
我们前面的线段树都是堆式存储法,要开4 4 4
那对于每一个节点,我们要记录它的左儿子和右儿子的编号,我们就只需要开两倍空间了!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 struct dynamicsegtree { struct node { int ls, rs, val; }; int n, cnt, lp, rp; vector<node> bit; explicit dynamicsegtree (int _n) : n(_n), cnt(0 ), lp(1 ), rp(_n) { bit.resize (n << 1 + 1 , {0 , 0 , 0 }); } void pushup (int x) { bit[x].val = bit[bit[x].ls].val + bit[bit[x].rs].val; } void update (int &x, int l, int r, int L, int R, int k) { if (!x) { x = ++cnt; } if (l == r) { bit[x].val += k; return ; } if (r < L || l > R) { return ; } int mid = (l + r) / 2 ; if (L <= mid) { update (bit[x].ls, l, mid, L, R, k); } if (mid < R) { update (bit[x].rs, mid + 1 , r, L, R, k); } pushup (x); } void update (int l, int r, int k) { assert (lp <= l && l <= r && r <= rp); int tp = 1 ; update (tp, 1 , n, l, r, k); } int query (int &x, int l, int r, int L, int R) { if (!x) { return 0 ; } if (r < L || l > R) { return 0 ; } if (L <= l && r <= R) { return bit[x].val; } return query (bit[x].ls, l, (l + r) / 2 , L, R) + query (bit[x].rs, (l + r) / 2 + 1 , r, L, R); } int query (int l, int r) { assert (lp <= l && l <= r && r <= rp); int tp = 1 ; return query (tp, 1 , n, l, r); } };
其实很好理解。
合并两棵树T 1 与 T 2 T_1与T_2 T 1 与 T 2
要是遇到两棵树其中一个没有的节点,我们可以像动态开点线段树那样新建一个节点。
没错,就是这么暴力
其实就是合并的逆过程。
我们需要新建一个新的树,然后直接从根节点往下递归,假设我们要分裂的区间是[ l , r ] [l,r] [ l , r ]
要是当前节点根本[ l , r ] [l,r] [ l , r ]
要是当前节点在
给出一个可重集 a a a 1 1 1
0 p x y:将可重集 p p p x x x y y y 2 2 2
1 p t:将可重集 t t t p p p t t t t t t
2 p x q:在 p p p x x x q q q
3 p x y:查询可重集 p p p x x x y y y
4 p k:查询在 p p p k k k -1。
第一行两个整数 n , m n,m n , m 1 ∼ n 1\sim n 1 ∼ n m m m
接下来一行 n n n 1 ∼ n 1 \sim n 1 ∼ n a a a ( a i ≤ m ) (a_{i} \leq m) ( a i ≤ m )
接下来的 m m m o p t opt o p t 0 ≤ o p t ≤ 4 0 \leq opt \leq 4 0 ≤ o p t ≤ 4 题目描述 为准。
依次输出每个查询操作的答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 5 12 0 0 0 0 0 2 1 1 1 2 1 1 2 2 1 1 3 3 1 1 3 4 1 2 2 1 1 4 2 1 1 5 0 1 2 4 2 2 1 4 3 2 2 4 1 1 2 4 1 3
对于 30 % 30\% 3 0 % 1 ≤ n ≤ 10 3 1\leq n \leq {10}^3 1 ≤ n ≤ 1 0 3 1 ≤ m ≤ 10 3 1 \le m \le {10}^3 1 ≤ m ≤ 1 0 3 100 % 100\% 1 0 0 % 1 ≤ n ≤ 2 × 10 5 1 \le n \le 2 \times {10}^5 1 ≤ n ≤ 2 × 1 0 5 1 ≤ x , y , q ≤ m ≤ 2 × 10 5 1 \le x, y, q \le m \le 2 \times {10}^5 1 ≤ x , y , q ≤ m ≤ 2 × 1 0 5
不开 long long 见祖宗!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 #include <bits/stdc++.h> using namespace std;#define int long long int n, m;int idx = 1 ;int val[222222 << 5 ];int ls[222222 << 5 ], rs[222222 << 5 ], root[222222 << 2 ], rub[222222 << 5 ], cnt, tot;int newnode () return cnt ? rub[cnt--] : ++tot; } void delnode (int &p) ls[p] = rs[p] = val[p] = 0 ; rub[++cnt] = p; p = 0 ; } void pushup (int p) val[p] = val[ls[p]] + val[rs[p]]; } void build (int L, int R, int &p) if (!p) { p = newnode (); } if (L == R) { cin >> val[p]; return ; } int mid = (L + R) / 2 ; build (L, mid, ls[p]); build (mid + 1 , R, rs[p]); pushup (p); } void update (int L, int R, int x, int c, int &p) if (!p) { p = newnode (); } if (L == R) { val[p] += c; return ; } int mid = (L + R) / 2 ; if (x <= mid) { update (L, mid, x, c, ls[p]); } else { update (mid + 1 , R, x, c, rs[p]); } pushup (p); } int merge (int p, int q, int L, int R) if (!p || !q) { return p + q; } if (L == R) { val[p] += val[q]; delnode (q); return p; } int mid = (L + R) / 2 ; ls[p] = merge (ls[p], ls[q], L, mid); rs[p] = merge (rs[p], rs[q], mid + 1 , R); pushup (p); delnode (q); return p; } void split (int &p, int &q, int l, int r, int L, int R) if (R < l || r < L) { return ; } if (!p) { return ; } if (l <= L && R <= r) { q = p; p = 0 ; return ; } if (!q) { q = newnode (); } int mid = (L + R) / 2 ; if (l <= mid) { split (ls[p], ls[q], l, r, L, mid); } if (mid < r) { split (rs[p], rs[q], l, r, mid + 1 , R); } pushup (p); pushup (q); } int query (int L, int R, int l, int r, int p) if (!p) { return 0 ; } if (l <= L && R <= r) { return val[p]; } int mid = (L + R) / 2 ; int ans = 0 ; if (l <= mid) { ans += query (L, mid, l, r, ls[p]); } if (mid < r) { ans += query (mid + 1 , R, l, r, rs[p]); } return ans; } int kth (int L, int R, int k, int p) if (L == R) { return L; } int mid = (L + R) / 2 ; int left = val[ls[p]]; if (k <= left) { return kth (L, mid, k, ls[p]); } else { return kth (mid + 1 , R, k - left, rs[p]); } } signed main () cin >> n >> m; build (1 , n, root[1 ]); while (m--) { int ch; cin >> ch; if (ch == 0 ) { int p, l, r; cin >> p >> l >> r; split (root[p], root[++idx], l, r, 1 , n); } else if (ch == 1 ) { int p, r; cin >> p >> r; root[p] = merge (root[p], root[r], 1 , n); } else if (ch == 2 ) { int p, l, r; cin >> p >> l >> r; update (1 , n, r, l, root[p]); } else if (ch == 3 ) { int p, r, l; cin >> p >> r >> l; cout << query (1 , n, r, l, root[p]) << '\n' ; } else { int p, k; cin >> p >> k; if (val[root[p]] < k) { cout << -1 << '\n' ; } else { cout << kth (1 , n, k, root[p]) << '\n' ; } } } return 0 ; }
一种卡常技巧,只能拿来卡静态线段树,并且有运算优先级的问题卡不了。
这里平均例题已经达到蓝以上了,大佬们选择性地看即可。
前置知识:抽象代数 线性代数 不然后面的东西你会非常难理解
这里就不得不推荐一下这篇让我茅塞顿开的博客 了 %%%%%%%%% (不要问我怎么找到的
前面的内容学起来感觉让你是比较有图形感的,但是后面的东西会出现大量公式袭击,所以我会说抽象。
要是你学过线段树和懒标记的话,你肯定知道,对于每一个节点我们都要维护一个节点的信息和标记(我不说懒了)。 那我们对于每个节点就要维护两个信息( D , T ) (D, T) ( D , T )
那我们就要维护3 3 3
merge( \text{merge(} merge( D 1 , D 2 D_1,D_2 D 1 , D 2 ) \text{)} ) D 1 , D 2 D_1,D_2 D 1 , D 2
compose( \text{compose(} compose( T 2 , T 1 T_2,T_1 T 2 , T 1 ) \text{)} ) T 2 , T 1 T_2,T_1 T 2 , T 1
apply( \text{apply(} apply( T , D T,D T , D ) \text{)} ) T T T D D D
设 T T T ⋅ : T × T → T \cdot: T \times T \to T ⋅ : T × T → T e ∈ T e \in T e ∈ T
结合律:( t 1 ⋅ t 2 ) ⋅ t 3 = t 1 ⋅ ( t 2 ⋅ t 3 ) (t_1 \cdot t_2) \cdot t_3 = t_1 \cdot (t_2 \cdot t_3) ( t 1 ⋅ t 2 ) ⋅ t 3 = t 1 ⋅ ( t 2 ⋅ t 3 )
单位元:e ⋅ t = t ⋅ e = t e \cdot t = t \cdot e = t e ⋅ t = t ⋅ e = t
则称 ( T , ⋅ , e ) (T, \cdot, e) ( T , ⋅ , e )
设 D D D + : D × D → D +: D \times D \to D + : D × D → D ϵ ∈ D \epsilon \in D ϵ ∈ D
结合律:( d 1 + d 2 ) + d 3 = d 1 + ( d 2 + d 3 ) (d_1 + d_2) + d_3 = d_1 + (d_2 + d_3) ( d 1 + d 2 ) + d 3 = d 1 + ( d 2 + d 3 )
交换律:d 1 + d 2 = d 2 + d 1 d_1 + d_2 = d_2 + d_1 d 1 + d 2 = d 2 + d 1
单位元:ϵ + d = d + ϵ = d \epsilon + d = d + \epsilon = d ϵ + d = d + ϵ = d
则称 ( D , + , ϵ ) (D, +, \epsilon) ( D , + , ϵ )
标记作用于信息的操作可以形式化为作用函数 ⊳ : T × D → D \vartriangleright: T \times D \to D ⊳ : T × D → D
单位元作用 :e ⊳ d = d e \vartriangleright d = d e ⊳ d = d 作用分配律 :t ⊳ ( d 1 + d 2 ) = ( t ⊳ d 1 ) + ( t ⊳ d 2 ) t \vartriangleright (d_1 + d_2) = (t \vartriangleright d_1) + (t \vartriangleright d_2) t ⊳ ( d 1 + d 2 ) = ( t ⊳ d 1 ) + ( t ⊳ d 2 ) 作用结合律 :( t 1 ⋅ t 2 ) ⊳ d = t 1 ⊳ ( t 2 ⊳ d ) (t_1 \cdot t_2) \vartriangleright d = t_1 \vartriangleright (t_2 \vartriangleright d) ( t 1 ⋅ t 2 ) ⊳ d = t 1 ⊳ ( t 2 ⊳ d )
这些性质保证了线段树操作的正确性和一致性。
对于区间加+区间乘,可以把标记 ( a , b ) (a,b) ( a , b ) 仿射变换矩阵 :
( a b 0 1 ) ( D 1 ) = ( a D + b 1 ) \begin{pmatrix}
a & b \\
0 & 1
\end{pmatrix}
\begin{pmatrix}
D \\
1
\end{pmatrix}
=
\begin{pmatrix}
aD+b \\
1
\end{pmatrix}
( a 0 b 1 ) ( D 1 ) = ( a D + b 1 )
矩阵乘法天然满足结合律
分配律由矩阵乘法对加法的分配性保证
单位元是 ( 1 0 0 1 ) \begin{pmatrix}1&0\\0&1\end{pmatrix} ( 1 0 0 1 )
当 D D D 分块矩阵 :
( a 0 b 0 a 2 2 a b 0 0 1 ) ( ∑ x ∑ x 2 1 ) = ( a ∑ x + b a 2 ∑ x 2 + 2 a b ∑ x + b 2 1 ) \begin{pmatrix}
a & 0 & b \\
0 & a^2 & 2ab \\
0 & 0 & 1
\end{pmatrix}
\begin{pmatrix}
\sum x \\
\sum x^2 \\
1
\end{pmatrix}
=
\begin{pmatrix}
a\sum x+b \\
a^2\sum x^2+2ab\sum x+b^2 \\
1
\end{pmatrix}
⎝ ⎛ a 0 0 0 a 2 0 b 2 a b 1 ⎠ ⎞ ⎝ ⎛ ∑ x ∑ x 2 1 ⎠ ⎞ = ⎝ ⎛ a ∑ x + b a 2 ∑ x 2 + 2 a b ∑ x + b 2 1 ⎠ ⎞
(时间复杂度允许你这么乱玩吗)
先给一个P3372 按照这个思路的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 #include <bits/stdc++.h> using namespace std;#define int long long struct lazytag { int x; lazytag (int _x = 0 ): x (_x) {} void compose (const lazytag &v) x += v.x; } }; struct data { int l; int s; data () {} data (int _s): l (1 ), s (_s) {} data (int _l, int _s): l (_l), s (_s) {} void apply (const lazytag &v) s += l * v.x; } friend data operator + (const data &d1, const data &d2) { return data (d1.l + d2.l , d1. s + d2. s); } }; template <class data , class lazytag >struct segtree { const int n; vector<data> d; vector<lazytag> t; void update (int x) d[x] = d[x << 1 ] + d[x << 1 | 1 ]; } template <class T> segtree (int _n, const vector<T> &a) : n(_n), d(n << 2 ), t(n << 2 ) { function<void (int , int , int )> build = [&](int x, int l, int r) { if (l == r) { d[x] = a[l]; return ; } int mid = (l + r) >> 1 ; build (x << 1 , l, mid), build (x << 1 | 1 , mid + 1 , r); update (x); }; build (1 , 1 , n); } void apply (int x, const lazytag &v) d[x].apply (v); t[x].compose (v); } void pushdown (int x) apply (x << 1 , t[x]), apply (x << 1 | 1 , t[x]); t[x] = lazytag (); } void update (int x, int l, int r, int L, int R, const lazytag &v) if (l == L && r == R) { apply (x, v); return ; } pushdown (x); int mid = (l + r) >> 1 ; if (R <= mid) { update (x << 1 , l, mid, L, R, v); } else if (L > mid) { update (x << 1 | 1 , mid + 1 , r, L, R, v); } else { update (x << 1 , l, mid, L, mid, v), update (x << 1 | 1 , mid + 1 , r, mid + 1 , R, v); } update (x); } void update (int L, int R, const lazytag &v) update (1 , 1 , n, L, R, v); } data query (int x, int l, int r, int L, int R) { if (l == L && r == R) { return d[x]; } pushdown (x); int mid = (l + r) >> 1 ; if (R <= mid) { return query (x << 1 , l, mid, L, R); } else if (L > mid) { return query (x << 1 | 1 , mid + 1 , r, L, R); } else { return query (x << 1 , l, mid, L, mid) + query (x << 1 | 1 , mid + 1 , r, mid + 1 , R); } } data query (int L, int R) { return query (1 , 1 , n, L, R); } }; signed main () int n, q; cin >> n >> q; vector<int > a (n + 1 ) ; for (int i = 1 ; i <= n; i++) { cin >> a[i]; } segtree<data, lazytag> seg (n, a) ; for (int i = 1 ; i <= q; i++) { int ch; cin >> ch; if (ch == 1 ) { int l, r, k; cin >> l >> r >> k; seg.update (l, r, k); } else { int l, r; cin >> l >> r; cout << seg.query (l, r).s << '\n' ; } } return 0 ; }
然后我们拿我们前面举过的例子,也就是要维护区间加、乘法,查询区间和的问题:
题目链接
如题,已知一个数列 a a a
将某区间每一个数乘上 x x x
将某区间每一个数加上 x x x
求出某区间每一个数的和。
第一行包含三个整数 n , q , m n,q,m n , q , m
第二行包含 n n n i i i i i i a i a_i a i
接下来 q q q
操作 1 1 1 1 x y k 含义:将区间 [ x , y ] [x,y] [ x , y ] k k k
操作 2 2 2 2 x y k 含义:将区间 [ x , y ] [x,y] [ x , y ] k k k
操作 3 3 3 3 x y 含义:输出区间 [ x , y ] [x,y] [ x , y ] m m m
输出包含若干行整数,即为所有操作 3 3 3
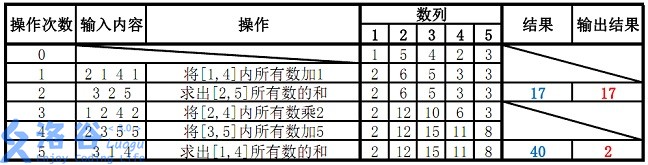
1 2 3 4 5 6 7 5 5 38 1 5 4 2 3 2 1 4 1 3 2 5 1 2 4 2 2 3 5 5 3 1 4
【数据范围】
对于 30 % 30\% 3 0 % n ≤ 8 n \le 8 n ≤ 8 q ≤ 10 q \le 10 q ≤ 1 0 70 % 70\% 7 0 % , , , 100 % 100\% 1 0 0 % 1 ≤ n ≤ 1 0 5 1 \le n \le 10^5 1 ≤ n ≤ 1 0 5 1 ≤ q ≤ 1 0 5 , 1 ≤ a i , k ≤ 1 0 4 1 \le q \le 10^5,1\le a_i,k\le 10^4 1 ≤ q ≤ 1 0 5 , 1 ≤ a i , k ≤ 1 0 4
除样例外,m = 571373 m = 571373 m = 5 7 1 3 7 3
样例说明:
故输出应为 17 17 1 7 2 2 2 40 m o d 38 = 2 40 \bmod 38 = 2 4 0 m o d 3 8 = 2
如果你看懂了这个东西,相信你已经对这道题胸有成竹了,那我就带你再过一遍思路:
我们对于每个节点维护一个信息D D D D D D ( 1 , 0 ) (1,0) ( 1 , 0 )
三个函数的实现不再细讲,不懂的人可以上去看。
AC记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 #include <bits/stdc++.h> using namespace std;#define int long long int mod; struct lazytag { int add, mul; lazytag (int _add = 0 , int _mul = 1 ): add (_add), mul (_mul) {} void compose (const lazytag &v) add = (add * v.mul + v.add) % mod; mul = (mul * v.mul) % mod; } }; struct data { int l; int s; data () {} data (int _s): l (1 ), s (_s % mod) {} data (int _l, int _s): l (_l), s (_s % mod) {} void apply (const lazytag &v) s = (s * v.mul + l * v.add) % mod; } friend data operator + (const data &d1, const data &d2) { return data (d1.l + d2.l , (d1. s + d2. s) % mod); } }; template <class data , class lazytag >struct segtree { const int n; vector<data> d; vector<lazytag> t; void update (int x) d[x] = d[x << 1 ] + d[x << 1 | 1 ]; } template <class T> segtree (int _n, const vector<T> &a) : n(_n), d(n << 2 ), t(n << 2 ) { function<void (int , int , int )> build = [&](int x, int l, int r) { t[x] = lazytag (0 , 1 ); if (l == r) { d[x] = a[l]; return ; } int mid = (l + r) >> 1 ; build (x << 1 , l, mid), build (x << 1 | 1 , mid + 1 , r); update (x); }; build (1 , 1 , n); } void apply (int x, const lazytag &v) d[x].apply (v); t[x].compose (v); } void pushdown (int x) apply (x << 1 , t[x]), apply (x << 1 | 1 , t[x]); t[x] = lazytag (0 , 1 ); } void update (int x, int l, int r, int L, int R, const lazytag &v) if (l == L && r == R) { apply (x, v); return ; } pushdown (x); int mid = (l + r) >> 1 ; if (R <= mid) { update (x << 1 , l, mid, L, R, v); } else if (L > mid) { update (x << 1 | 1 , mid + 1 , r, L, R, v); } else { update (x << 1 , l, mid, L, mid, v); update (x << 1 | 1 , mid + 1 , r, mid + 1 , R, v); } update (x); } void update_add (int L, int R, int v) update (1 , 1 , n, L, R, lazytag (v % mod, 1 )); } void update_mul (int L, int R, int v) update (1 , 1 , n, L, R, lazytag (0 , v % mod)); } data query (int x, int l, int r, int L, int R) { if (l == L && r == R) { return d[x]; } pushdown (x); int mid = (l + r) >> 1 ; if (R <= mid) { return query (x << 1 , l, mid, L, R); } else if (L > mid) { return query (x << 1 | 1 , mid + 1 , r, L, R); } else { return query (x << 1 , l, mid, L, mid) + query (x << 1 | 1 , mid + 1 , r, mid + 1 , R); } } data query (int L, int R) { return query (1 , 1 , n, L, R); } }; signed main () int n, q; cin >> n >> q >> mod; vector<int > a (n + 1 ) ; for (int i = 1 ; i <= n; i++) { cin >> a[i]; a[i] %= mod; } segtree<data, lazytag> seg (n, a) ; for (int i = 1 ; i <= q; i++) { int ch; cin >> ch; if (ch == 1 ) { int l, r, k; cin >> l >> r >> k; seg.update_mul (l, r, k); } else if (ch == 2 ) { int l, r, k; cin >> l >> r >> k; seg.update_add (l, r, k); } else { int l, r; cin >> l >> r; cout << seg.query (l, r).s << '\n' ; } } return 0 ; }
当DP满足区间可加性 时:
d p l , r = ⨁ k = l r − 1 d p l , k ⊗ d p k + 1 , r dp_{l,r} = \bigoplus_{k=l}^{r-1} dp_{l,k} \otimes dp_{k+1,r}
d p l , r = k = l ⨁ r − 1 d p l , k ⊗ d p k + 1 , r
可把DP状态看成半群元素,用线段树维护:
例:最优括号化(矩阵链乘)、凸包DP(用闵可夫斯基和作为运算)
讲一个比较经典的例题吧:
有 N N N i ( i > 1 ) i(i>1) i ( i > 1 ) 1 1 1 D i D_i D i K K K i i i C i C_i C i i i i S i S_i S i i i i W i W_i W i
输入文件的第一行包含两个整数 N , K N,K N , K
第二行包含 N − 1 N-1 N − 1 D 2 , D 3 , ⋯ , D N D_2,D_3,\cdots,D_N D 2 , D 3 , ⋯ , D N N − 1 N-1 N − 1
第三行包含 N N N C 1 , C 2 , ⋯ , C N C_1,C_2,\cdots,C_N C 1 , C 2 , ⋯ , C N
第四行包含 N N N S 1 , S 2 , ⋯ , S N S_1,S_2,\cdots,S_N S 1 , S 2 , ⋯ , S N
第五行包含 N N N W 1 , W 2 , ⋯ , W N W_1,W_2,\cdots,W_N W 1 , W 2 , ⋯ , W N
输出文件中仅包含一个整数,表示最小的总费用。
1 2 3 4 5 3 2 1 2 2 3 2 1 1 0 10 20 30
30 % 30\% 3 0 % N ≤ 500 N \leq 500 N ≤ 5 0 0
100 % 100\% 1 0 0 % K ≤ N K\leq N K ≤ N K ≤ 100 K\leq 100 K ≤ 1 0 0 N ≤ 2 × 1 0 4 N\leq 2\times 10^4 N ≤ 2 × 1 0 4 D i ≤ 1 0 9 D_i \leq 10^9 D i ≤ 1 0 9 C i ≤ 1 0 4 C_i\leq 10^4 C i ≤ 1 0 4 S i ≤ 1 0 9 S_i \leq10^9 S i ≤ 1 0 9 W i ≤ 1 0 4 W_i \leq 10^4 W i ≤ 1 0 4
首先很显然的DP \text{DP} DP d p i , j dp_{i,j} d p i , j i i i j j j
那状态转移:
d p i , j = m i n { d p k , j − 1 + c o s t ( k , i ) } + c i dp_{i,j}=min\left\{ dp_{k,j-1}+cost(k,i)\right\} + c_i d p i , j = m i n { d p k , j − 1 + c o s t ( k , i ) } + c i
这里c o s t ( k , i ) cost(k,i) c o s t ( k , i ) i i i k k k
这里j j j
d p i = m i n { d p k + c o s t ( k , i ) } + c i dp_i = min\left\{ dp_k + cost(k, i)\right\} + c_i d p i = m i n { d p k + c o s t ( k , i ) } + c i ( j − 1 ≤ k < i ) (j - 1 \leq k < i) ( j − 1 ≤ k < i )
一看数据范围就发现了时间复杂度根本不对,所以我们要想办法优化。
我们可以对于每个村庄记录两个值l l l r r r
然后对于第一个村庄到第l i − 1 l_i - 1 l i − 1 i i i d p k + c o s t ( k , i ) dp_k + cost(k,i) d p k + c o s t ( k , i )
我们直接上例题!
Rick 和他的同事们做出了一种新的放射性配方,与此同时很多坏人正追赶着他们。因此 Rick 想在坏人们捉到他之前把他的遗产留给 Morty。
在宇宙中一共有 n n n 1 ∼ n 1\sim n 1 ∼ n s s s
众所周知,Rick 有一个传送枪,他用这把枪可以制造出一个从他所在的星球通往其他星球(也包括自己所在的星球)的单行道路。但是由于他还在用免费版,因此这把枪的使用是有限制的。
默认情况下他不能用这把枪开启任何传送门。在网络上有 q q q
网络上一共有三种方案可供购买:
开启一扇从星球 v v v u u u
开启一扇从星球 v v v [ l , r ] [l,r] [ l , r ]
开启一扇从标号在 [ l , r ] [l,r] [ l , r ] v v v
Rick 并不知道 Morty 在哪儿,但是 Unity 将要通知他 Morty 的具体位置,并且他想要赶快找到通往所有星球的道路各一条并立刻出发。因此对于每一个星球(包括地球本身)他想要知道从地球到那个星球所需的最小钱数。
输入数据的第一行包括三个整数 n , q , s n,q,s n , q , s
接下来的 q q q q q q
输入 1 v u w 表示第一种方案,其中 v , u v,u v , u w w w
输入 2 v l r w 表示第二种方案,其中 v , l , r v,l,r v , l , r w w w
输入 3 v l r w 表示第三种方案,其中 v , l , r v,l,r v , l , r w w w
输出一行用空格隔开的 n n n i i i − 1 -1 − 1
1 2 3 4 5 6 3 5 1 2 3 2 3 17 2 3 2 2 16 2 2 2 3 3 3 3 1 1 12 1 3 3 17
1 2 3 4 4 3 1 3 4 1 3 12 2 2 3 4 10 1 2 4 16
样例解释:在第一组测试样例里,Rick 可以先购买第 4 4 4 2 2 2 2 2 2
对于 100 % 100\% 1 0 0 % 1 ≤ n , q ≤ 1 0 5 , 1 ≤ w ≤ 1 0 9 , 1 ≤ l , r ≤ n 1\leq n,q\leq10^5,1\leq w\leq10^9,1\leq l,r\leq n 1 ≤ n , q ≤ 1 0 5 , 1 ≤ w ≤ 1 0 9 , 1 ≤ l , r ≤ n
首先抛开数据范围不谈,这题就是很简单的最短路,直接对着题面无脑连边跑dijkstra \text{dijkstra} dijkstra
但n , q n,q n , q
题目里都有区间 这两个和线段树密切相关的字,所以我们考虑线段树。
我们线段树的每个节点都表示了一段区间,我们点向区间连边的时候直接把这个点往树上对应的区间连边即可。
然后可能还有区间连向点的情况,这里我们只需再建一棵树维护这种情况即可。
Oi-Wiki-线段树
_rqy的博客-线段树维护分治信息略解
dengstar的博客-[线段树进阶〇]“抽象”化的线段树
《深入浅出程序设计竞赛(进阶篇)》P099P112,P130 P142
《信息学奥林匹克辞典》,P150~P152, P270~P271
《算法竞赛》,P175~P210
《组合数学》P168~P175
国家集训队论文 2004 林涛:《线段树的应用》
在此一并致谢这些作者们。%%%
本文由作者hsl_beat独立完成